
A dicembre, Apple sarà protagonista a NeurIPS 2025, una delle conferenze di riferimento mondiali per il machine learning, dove presenterà sette studi e una serie di demo su Apple silicon.
In parallelo, i ricercatori dApple hanno pubblicato un paper che spiega come usare i large language model per capire cosa stiamo facendo a partire da audio e dati di movimento.
In pratica, Apple sta lavorando sia sulle fondamenta teoriche dell’AI, sia su applicazioni molto concrete per Apple Watch, iPhone e per tutto quello che chiama Apple Intelligence.
Apple e NeurIPS 2025
NeurIPS 2025 si terrà a San Diego dal 2 al 7 dicembre (con un evento satellite a Città del Messico dal 30 novembre al 5 dicembre) e Apple arriva con un pacchetto di ricerche decisamente denso.
I paper confermati coprono tre grandi aree.
Privacy e raccolta dati sicura
Con lavori come “Instance-Optimality for Private KL Distribution Estimation”, “Privacy Amplification by Random Allocation” e “PREAMBLE: Private and Efficient Aggregation via Block Sparse Vectors”, Apple prova a rispondere a una domanda chiave: come sfruttare i dati di milioni di utenti senza sacrificare la privacy? Si parla di differential privacy, tecniche di campionamento e aggregazione sicura, tutte cose che stanno dietro alla promessa di Apple Intelligence “privacy-first”.
Limiti dei modelli di ragionamento
“The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity” è forse il titolo più discusso: il paper analizza come cambiano le prestazioni dei modelli man mano che i problemi diventano più complessi e mostra che, oltre una certa soglia, l’accuratezza crolla anche quando il modello avrebbe “budget di token” sufficiente. L’idea è capire non solo che cosa rispondono i modelli, ma come arrivano a quella risposta.
Nuove tecniche per la generative AI
“STARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis” propone un approccio più efficiente per generare immagini ad alta risoluzione, riducendo i costi rispetto ai classici diffusion model. “LinEAS: End-to-end Learning of Activation Steering with a Distributional Loss” lavora invece sul controllo del comportamento dei modelli, per mitigare ad esempio tossicità e contenuti indesiderati. “Scaling Laws for Optimal Data Mixtures” studia come mescolare al meglio dataset diversi per allenare modelli più stabili ed efficaci.
Interessante anche la parte “politica” della presenza Apple: l’azienda sponsorizza affinity group come Women in Machine Learning, LatinX in AI e Queer in AI, con presenza attiva dei propri dipendenti, segnale che vuole essere vista non solo come big tech che porta paper, ma come attore che investe nella comunità di ricerca.
Le demo su MLX e FastVLM
NeurIPS non sarà solo slide e PDF, ma anche demo live allo stand Apple (booth #1103). Qui Cupertino mostra il lato “prodotto” della ricerca:
MLX è il framework open source di Apple per il machine learning su Apple silicon, pensato per sfruttare CPU e GPU con memoria unificata. In fiera vedremo:
- generazione di immagini con un large diffusion model su un iPad Pro con chip M5
- text e code generation con un modello da 1 trilione di parametri che gira in Xcode su un cluster di quattro Mac Studio con M3 Ultra, ognuno con 512 GB di memoria unificata.
FastVLM è una famiglia di modelli vision–linguaggio “mobile-first”, costruiti proprio su MLX, che usano una combinazione di CNN e Transformer per elaborare immagini ad alta risoluzione in modo rapido. A NeurIPS Apple mostra una demo di domanda–risposta visiva in tempo reale su iPhone 17 Pro Max: inquadri una scena, fai una domanda testuale, il modello risponde.
La ricerca su audio, movimento e attività dell’utente

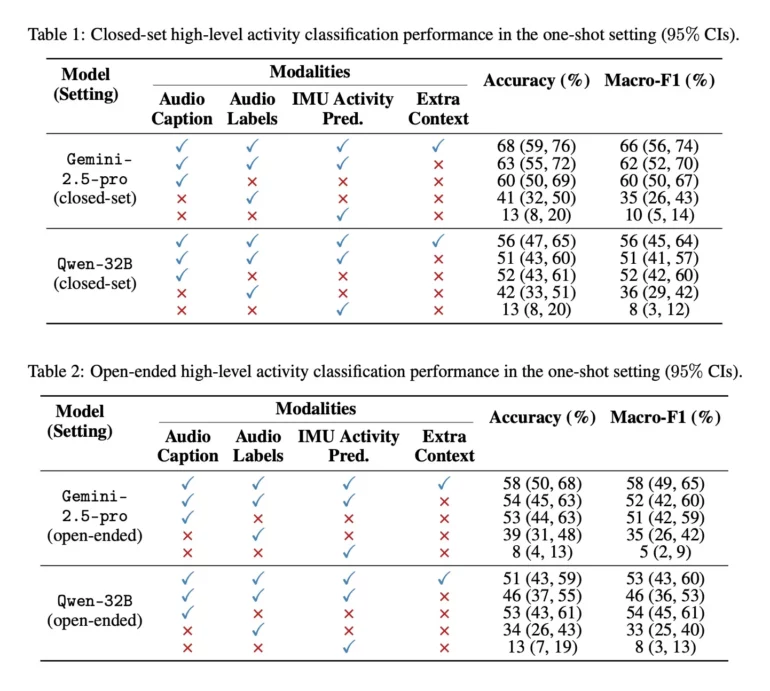
Dentro questo quadro si inserisce un altro tassello: il paper “Using LLMs for Late Multimodal Sensor Fusion for Activity Recognition”, pubblicato dai ricercatori Apple e accettato a un workshop di NeurIPS dedicato al time series per la salute.
L’idea è quella di usare i large language model come “collante” per fondere informazioni provenienti da sensori diversi – in questo caso audio e movimento – e capire cosa sta facendo l’utente.
Invece di addestrare un grosso modello multimodale end-to-end, Apple segue un approccio a stadi:
- i dati audio vengono passati a modelli che generano brevi descrizioni testuali e label di attività
- i dati di movimento (accelerometro, giroscopio, quindi un tipico IMU) vengono elaborati da un altro modello, che produce previsioni di attività
Queste informazioni vengono fuse in ingresso a un LLM generalista (nel paper si citano Gemini 2.5 Pro e Qwen 32B) per classificare l’attività in corso
Il punto chiave è che il LLM non vede direttamente l’audio grezzo, ma solo “riassunti” testuali e predizioni dall’IMU: questo riduce i problemi di privacy e rende riutilizzabili LLM già esistenti, senza addestrare modelli multimodali giganteschi ad hoc.
Per testare l’approccio, Apple usa una porzione del dataset Ego4D, una raccolta enorme di video in prima persona che copre attività quotidiane e sport. I ricercatori selezionano clip di 20 secondi di dodici attività ad alto livello: pulire con l’aspirapolvere, cucinare, fare il bucato, mangiare, giocare a basket, giocare a calcio, giocare con animali domestici, leggere un libro, usare il computer, lavare i piatti, guardare la TV, allenarsi/sollevare pesi.
Il messaggio è chiaro: se metti insieme sensori diversi e usi un LLM come livello di fusione tardiva, riesci a capire meglio cosa sta succedendo anche quando i dati grezzi, presi da soli, non basterebbero.
Prodotti consigliati



Prova la nuova sezione commenti!